Contents
Codes / data / videos / readings
Introduction to texts https://aeturrell.github.io/coding-for-economists/text-intro.html#text-intro https://kunststube.net/encoding/ sentiment analysis: A simple sentiment analysis using various models and libraries https://nbviewer.org/github/cyrus723/my-first-binder/blob/main/sentiment_analysis_1_all_models.ipynb https://realpython.com/sentiment-analysis-python/ topic modeling finance papers - topic modeling Analyst Information Discovery and Interpretation Roles: A Topic Modeling Approach | Management Science (informs.org) Measuring Corporate Culture Using Machine Learning | The Review of Financial Studies | Oxford Academic (oup.com) gensim example for topic modeling, LDA https://nbviewer.org/github/cyrus723/my-first-binder/blob/main/nlp_lda_model_gensim1_spacy.ipynb#topic=4&lambda=1&term= LDA from scikit site Topic extraction with Non-negative Matrix Factorization and Latent Dirichlet Allocation — scikit-learn 1.4.2 documentation https://github.com/tatsath/fin-ml/blob/master/Chapter%2010%20-%20Natural%20Language%20Processing/NLP-MasterTemplate.ipynb data text data from scikit learn site 7.2. Real world datasets — scikit-learn 1.4.2 documentation text classification https://realpython.com/python-keras-text-classification/ word embedding https://www.tensorflow.org/text/guide/word_embeddings https://en.wikipedia.org/wiki/Word_embedding Efficient Non-parametric Estimation of Multiple Embeddings per Word in Vector Space: http://arxiv.org/pdf/1504.06654v1 Comparison Between BagofWords and Word2Vec — PyImageSearch: https://pyimagesearch.com/2022/07/18/comparison-between-bagofwords-and-word2vec/ https://radimrehurek.com/gensim/models/word2vec.html The amazing power of word vectors: https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/ Understanding NLP Word Embeddings — Text Vectorization: https://towardsdatascience.com/understanding-nlp-word-embeddings-text-vectorization-1a23744f7223 https://nlp.stanford.edu/projects/glove/ https://spacy.io/usage/models https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf Twitter Data Collection Tutorial with Python: https://towardsdatascience.com/twitter-data-collection-tutorial-using-python-3267d7cfa93Links to an external site. eLinks to an external site. Introduction to NLTK: https://www.nltk.org/#:~:text=Natural%20Language%20Processing%20with%20Python,aLinks to an external site. nalyzing%20linguistic%20structure%2C%20and%20moreLinks to an external site. DataCamp Text Analytics Tutorial: https://www.datacamp.com/community/tutorials/text-analytics-beginners-nltkLinks to an external site. Natural Language Processing with Transformers Book: https://transformersbook.com tokenization What is NLP (Natural Language Processing) Tokenization? — tokenex: https://www.tokenex.com/blog/ab-what-is-nlp-natural-language-processing-tokenization/ What is Tokenization | Tokenization In NLP: https://www.analyticsvidhya.com/blog/2020/05/what-is-tokenization-nlp/ CORPUS: https://hypersense.subex.com/aiglossary/corpus Text similarity search in Elasticsearch using vector fields | Elastic Blog: https://www.elastic.co/blog/text-similarity-search-with-vectors-in-elasticsearch Word, Subword, and Character-Based Tokenization: Know the Difference: https://towardsdatascience.com/word-subword-and-character-based-tokenization-know-the-difference-ea0976b64e17 How to use [HuggingFace’s] Transformers Pre-Trained tokenizers?: ttps://nlpiation.medium.com/how-to-use-huggingfaces-transformers-pre-trained-tokenizers-e029e8d6d1fa https://dev.mrdbourke.com/tensorflow-deep-learning/04_transfer_learning_in_tensorflow_part_1_feature_extraction/ videos https://youtu.be/zqVtHYFYQY8 https://youtu.be/zqVtHYFYQY8?t=1138
Introduction
Everything in NLP is discrete, meaning there is no predictable relationship between the forms and the meanings. On the other hand, neural networks are best at dealing with something numerical and continuous, meaning everything in neural networks needs to be float numbers. How can we “bridge” between these two worlds—discrete and continuous? The key is the use
of word embeddings. Technically, an embedding is a continuous vector representation of something that is usually discrete. A word embedding is a continuous vector representation of a word.

(from Hagiwara, 2021)
A neural network (also called an artificial neural network) is a generic mathematical model that transforms a vector to another vector. Neural networks are trainable. We usually group a number of instances together and feed them to a neural network, updating model parameters per each group, not per each instance. We call this group of instances a batch.
(from Hagiwara, 2021)
Pre-prosessing raw texts
Natural language process is a set of methods which map natural language units into a machine readable form. Once we can figure out how to represent language to a machine, we can then use statistical/mathematical tools to learn things about tests without having to read them by human. (SPAM filters, speech recognition, machine translation, information retrieval like Research engines, and artificial intelligence.)
tokenization – splits the document into tokens which can be words or n-grams or phrases, The purpose of tokenization is to create a vocabulary from a corpus. A corpus is a collection of texts (such as the dataset used to train an NLP model), and a vocabulary is the set of unique tokens found within the corpus.
removing formatting – punctuation, numbers, cases, spacing
stop word removal – removal of “stop words” like “if,” “but,” “or,” and so on
Normalizing words by condensing all forms of a word into a single form. Stemming and lemmatization are techniques used to reduce words to their root forms.
Stemming involves removing the suffixes from words, such as “ing” or “ed,” to reduce them to their base form. For example, the word “jumping” would be stemmed to “jump.” With stemming, a word is cut off at its stem, the smallest unit of that word from which you can create the descendant words. Stemming simply truncates the string using common endings, so it will miss the relationship between “feel” and “felt,” for example.
Lemmatization, however, involves reducing words to their base form based on their part of speech. For example, the word “jumped” would be lemmatized to “jump,” but the word “jumping” would be lemmatized to “jumping” since it is a present participle. Lemmatization process uses a data structure that relates all forms of a word back to its simplest form, or lemma. Because lemmatization is generally more powerful than stemming, it’s the only normalization strategy offered by spaCy.
Sources: from https://www.datacamp.com/tutorial/text-analytics-beginners-nltk
Stemming and Lemmatization in Python
Feature representation or vectorizing
Next feature representation – the preprocessed tokens need to be translated into predictive features, which means that a researcher needs to transform tokens to a digestible format by computer. Machine learning models take vectors (arrays of numbers) as input. When working with text, the first thing you must do is come up with a strategy to convert strings to numbers (or to “vectorize” the text) before feeding it to the model. We create vectors from tokens.
Representing text as numbers
These vectors are numerical representations of the meaning of a token and how it relates to other tokens in our vocabulary. A model is used to embed raw text into a vector space where we can use the data science tool. Vectorizing text by turning the text into a numerical representation for consumption by your classifier, Vectorization is a process that transforms a token into a vector, or a numeric array that, in the context of NLP, is unique to and represents various features of a token. Vectors are used under the hood to find word similarities, classify text, and perform other NLP operations. This particular representation is a dense array, one in which there are defined values for every space in the array. This is in opposition to earlier methods that used sparse arrays, in which most spaces are empty.
One-hot encodings : As a first idea, you might “one-hot” encode each word in your vocabulary. Consider the sentence “The cat sat on the mat”. The vocabulary (or unique words) in this sentence is (cat, mat, on, sat, the). To represent each word, you will create a zero vector with length equal to the vocabulary, then place a one in the index that corresponds to the word. This approach is shown in the following diagram.
Encode each word with a unique number: A second approach you might try is to encode each word using a unique number. Continuing the example above, you could assign 1 to “cat”, 2 to “mat”, and so on. You could then encode the sentence “The cat sat on the mat” as a dense vector like [5, 1, 4, 3, 5, 2]. This approach is efficient. Instead of a sparse vector, you now have a dense one (where all elements are full).
N-Grams is a sequence of n items in a sample of text. Depending on N, it’s called bigrams, trigrams, four-grams, and et cetera.
For example, “This is a sentence”.
Source: https://www.educative.io/answers/what-are-n-grams
Count vectorization: Creates a document-term matrix where the entry of each cell will be a count of the number of times that word occurred in that document.
TF-IDF is a technique to convert text to a numeric table representation.
- In this table, each row represents a document in the corpus.
- Each column represents a word in the corpus.
- Each cell in the table provides a value that indicates the relative strength of the word with respect to the document.
- A higher value indicates higher correlation between the word and the document.
- The rarer the word is, the higher that this value’s going to be.
- If a word occurs very frequently within a particular text message, so that’s TF, but very infrequently elsewhere, that’s going to be the second term.
- Then a very large number will be assigned, and it’ll be assumed to be very important to differentiating that text message from others.
- In summary, this method helps you pull out important but seldom-used words.
Example – vectorizing
sentences = ['John likes ice cream', 'John hates chocolate.'] from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer(min_df=0, lowercase=False) vectorizer.fit(sentences) vectorizer.vocabulary_ output:{'John': 0, 'chocolate': 1, 'cream': 2, 'hates': 3, 'ice': 4, 'likes': 5}vectorizer.transform(sentences).toarray() output:array([[1, 0, 1, 0, 1, 1], [1, 1, 0, 1, 0, 0]])
Count vectorization: Creates a document-term matrix where the entry of each cell will be a count of the number of times that word occurred in that document.
from sklearn.feature_extraction.text import CountVectorizer count_vect = CountVectorizer(analyzer=clean_text) X_counts = count_vect.fit_transform(data['body_text'])
N-gram
from sklearn.feature_extraction.text import CountVectorizer ngram_vect = CountVectorizer(ngram_range=(2,2)) #bi-gram X_counts = ngram_vect.fit_transform(data['cleaned_text'])
TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer tfidf_vect = TfidfVectorizer(analyzer=clean_text) X_tfidf = tfidf_vect.fit_transform(data['body_text'])
Word embeddings give us a way to use an efficient, dense representation in which similar words have a similar encoding. Importantly, you do not have to specify this encoding by hand. An embedding is a dense vector of floating point values (the length of the vector is a parameter you specify). Instead of specifying the values for the embedding manually, they are trainable parameters (weights learned by the model during training, in the same way a model learns weights for a dense layer). It is common to see word embeddings that are 8-dimensional (for small datasets), up to 1024-dimensions when working with large datasets. A higher dimensional embedding can capture fine-grained relationships between words, but takes more data to learn.
In natural language processing, “embedding” refers to the process of mapping non-vectorized data, such as tokens, into a vector space that has meaning for a machine learning model or neural network. By doing this, the model can learn the relationships between words and their meanings automatically rather than having to specify them manually. When you visualize word embeddings, you can think of the result as a map of the vocabulary that shows how one token is related to other tokens in terms of meaning. Each token is positioned near other tokens with similar meanings.
To give tokens meaning, the model must be trained on them. This allows the model to learn the meanings of words and how they relate to other words. To achieve this, the word vectors are “embedded” into an embedding space. As a result, similar words should have similar vectors after training.
Word2Vec essentially means expressing each word in your text corpus in an N-dimensional space (embedding space). The word’s weight in each dimension of that embedding space defines it for the model.
“Bag of words”
most text analysis methods treat documents as a big bunch of words or terms. Order is generally not taken into account, just word and term frequencies. There are ways to parse documents into ngrams or words
Drawbacks of BOW: the inclusion of many 0s in our matrix (i.e., a sparse matrix). A sparse matrix contains less information and wastes a lot of memory.
The biggest disadvantage in Bag-of-Words is the complete inability to learn grammar and semantics.
- Lack of meaningful relations and no consideration for order of words: Usually, a text is mainly represented by a BOW via a one-hot encoding strategy.
- Many latent and deep semantics among words and particularly the order or the contextual information of words are usually ignored.
- Sparse matrix: In the BOW model, each document is represented as a word-count vector. These counts can be binary counts, a word may occur in the text or not or will have absolute counts.
- The size of the vector is equal to the number of elements in the vocabulary. If most of the elements are zero then the bag of words will be a sparse matrix.
- Computationally intensive: In deep learning, sparse representations are harder to model for computational reasons.
- Huge amount of weights: Huge input vectors mean a huge number of weights for a neural network. More weights mean more computation required to train and predict.
- “Predicting word meaning based on its neighboring words (collocation), is generally one of the most common extensions beyond the simple bag of words approach.” (p. 27, LM, 2016)
Word Embedding is solution to these problems.
Sparse Matrix problem with BOW is solved by mapping high-dimensional data into a lower-dimensional space that preserves semantic relationships.
Lack of meaningful relationship issue of BOW is solved by placing vectors of semantically similar items close to each other. This way words that have similar meaning have similar distances in the vector space.
Source: https://www.tensorflow.org/text/guide/word_embeddings
Source: Chakraborty, D. “Word2Vec: A Study of Embeddings in NLP,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Thanki, eds., 2022, https://pyimg.co/2fb0z
Source: https://pyimagesearch.com/2022/07/11/word2vec-a-study-of-embeddings-in-nlp/
One-hot ending
As a first idea, you might "one-hot" encode each word in your vocabulary. Consider the sentence "The cat sat on the mat". The vocabulary (or unique words) in this sentence is (cat, mat, on, sat, the). To represent each word, you will create a zero vector with length equal to the vocabulary, then place a one in the index that corresponds to the word.from https://www.tensorflow.org/text/guide/word_embeddings
Word embedding
Word embeddings give us a way to use an efficient, dense representation in which similar words have a similar encoding. Importantly, you do not have to specify this encoding by hand. An embedding is a dense vector of floating point values (the length of the vector is a parameter you specify). Instead of specifying the values for the embedding manually, they are trainable parameters (weights learned by the model during training, in the same way a model learns weights for a dense layer). It is common to see word embeddings that are 8-dimensional (for small datasets), up to 1024-dimensions when working with large datasets. A higher dimensional embedding can capture fine-grained relationships between words, but takes more data to learn.from https://www.tensorflow.org/text/guide/word_embeddings https://www.tensorflow.org/text/tutorials/word_embeddings https://www.tensorflow.org/text/tutorials/warmstart_embedding_matrix https://www.tensorflow.org/text/tutorials/word2vec
The Difference Between a Token, a Vector, and an Embedding
To get to a point where your model can understand text, you first have to tokenize it, vectorize it and create embeddings from these vectors.
- Tokenization: This is the process of dividing the original text into individual pieces called tokens. Each token is assigned a unique id to represent it as a number.
- Vectorization: The unique ids are then assigned to randomly initialized n-dimensional vectors.
- Embedding: To give tokens meaning, the model must be trained on them. This allows the model to learn the meanings of words and how they relate to other words. To achieve this, the word vectors are “embedded” into an embedding space. As a result, similar words should have similar vectors after training.
Word embeddings
Help in the following use cases.
- Compute similar words
- Text classifications
- Document clustering/grouping
- Feature extraction for text classifications
- Natural language processing.
“WORD VECTORS are numerical vector representations of word semantics, or meaning, including literal and implied meaning. So word vectors can capture the connotation of words, like “peopleness,” “animalness,” “placeness,” “thingness,” and even “conceptness.” And they combine all that into a dense vector (no zeros) of floating point values. This dense vector
enables queries and logical reasoning.
Word2vec learns the meaning of words merely by processing a large corpus of unlabeled text. No one has to label the words in the Word2vec vocabulary. No one has to tell
the Word2vec algorithm that Marie Curie is a scientist, that the Timbers are a soccer
team, that Seattle is a city, or that Portland is a city in both Oregon and Maine. And no
one has to tell Word2vec that soccer is a sport, or that a team is a group of people, or
that cities are both places as well as communities. Word2vec can learn that and much
more, all on its own! All you need is a corpus large enough to mention Marie Curie and
Timbers and Portland near other words associated with science or soccer or cities.”
“Instead of trying to train a neural network to learn the target word meanings directly
(on the basis of labels for that meaning), you teach the network to predict words near
the target word in your sentences. So in this sense, you do have labels: the nearby
words you’re trying to predict. But because the labels are coming from the dataset
itself and require no hand-labeling”
The process of converting words into numbers are called Vectorization. Word Embeddings is one of vectorization and is a methodology in NLP to map words or phrases from vocabulary to a corresponding vector of real numbers which used to find word predictions, word similarities/semantics. After the words are converted as vectors, we need to use some techniques such as Euclidean distance, Cosine Similarity to identify similar words.
Why Cosine Similarity Count the common words or Euclidean distance is the general approach used to match similar documents which are based on counting the number of common words between the documents. This approach will not work even if the number of common words increases but the document talks about different topics. To overcome this flaw, the “Cosine Similarity” approach is used to find the similarity between the documents. Mathematically, it measures the cosine of the angle between two vectors (item1, item2)
projected in an N-dimensional vector space. The advantageous of cosine similarity is,
it predicts the document similarity even Euclidean is distance.
Word embeddings coming from pre-trained methods such as,
Word2Vec — From Google
Fasttext — From Facebook
Glove — From Standford
Word embedding example
Word embeddings are a type of word representation that allows words with similar meanings to have a similar representation. They are typically generated using algorithms like Word2Vec, GloVe, or FastText which process a large corpus of text and learn to represent each word with dense vectors (arrays of floating points) that capture semantic meanings.
Source: https://towardsdatascience.com/understanding-nlp-word-embeddings-text-vectorization-1a23744f7223
To illustrate how word embeddings can be analyzed using Euclidean distance, we’ll use the same hypothetical word vectors I described earlier and compute the distances between a few pairs of words. This will show how similar or dissimilar words are to each other in the embedding space.
Here are the word vectors again:
- apples: [0.9, 0.1, 0.8]
- oranges: [0.9, 0.2, 0.8]
- eating: [0.3, 0.8, 0.2]
- fruits: [0.7, 0.3, 0.9]
- enjoy: [0.4, 0.9, 0.1]
- like: [0.5, 0.9, 0.1]
To compute the Euclidean distance between two vectors, you use the formula:

Interpretation
- The distance between “apples” and “oranges” is small (0.1), indicating high similarity, which makes sense as both are fruits.
- The distance between “enjoy” and “like” is also small (0.1), showing that these verbs are considered similar in meaning.
- The distance between “apples” and “eating” is larger (1.1), reflecting their different roles and meanings in language (one being a noun/fruit and the other a verb/action).
These distances provide a numeric measure of the “semantic distance” between words, according to the learned embeddings. Lower distances suggest closer semantic relationships. This method can be a powerful tool for many natural language processing applications.
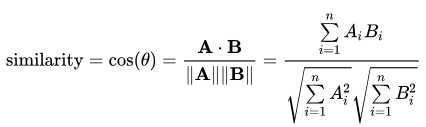
Sources: https://arxiv.org/pdf/1301.3781.pdf
https://www.machinelearningplus.com/nlp/cosine-similarity/
https://medium.com/@adriensieg/text-similarities-da019229c894
Example from Chat GPT: Show an example of document term matrix and cosine similarity using the real-world example
Step 1: Define the Documents
Let’s consider three short text documents as our corpus:
- Document 1: “Apple and orange are popular fruits.”
- Document 2: “Microsoft and Apple are leading tech companies.”
- Document 3: “I like to eat apple and orange.”
Step 2: Create the Document-Term Matrix
A Document-Term Matrix represents documents as rows and terms (or words) as columns. Each cell in the matrix represents the frequency of a term in a document. For simplicity, we will ignore common stop words like “and”, “are”, “to”, etc., and we won’t apply stemming or lemmatization:


This result shows a relatively low similarity between Document 1 and Document 2, which is expected given their different contexts (fruits vs tech companies).
Using a similar approach, you can calculate cosine similarity between other pairs of documents to determine how closely related they are in terms of their content. This type of analysis is fundamental in systems like search engines, recommendation systems, and more sophisticated natural language processing tasks.
Lexicon-based analysis
This type of analysis, such as the NLTK Vader sentiment analyzer, involves using a set of predefined rules and heuristics to determine the sentiment of a piece of text. These rules are typically based on lexical and syntactic features of the text, such as the presence of positive or negative words and phrases.
While lexicon-based analysis can be relatively simple to implement and interpret, it may not be as accurate as ML-based or transformed-based approaches, especially when dealing with complex or ambiguous text data.
Machine learning (ML)
This approach involves training a model to identify the sentiment of a piece of text based on a set of labeled training data. These models can be trained using a wide range of ML algorithms, including decision trees, support vector machines (SVMs), and neural networks.
ML-based approaches can be more accurate than rule-based analysis, especially when dealing with complex text data, but they require a larger amount of labeled training data and may be more computationally expensive.
Pre-trained transformer-based deep learning
A deep learning-based approach, as seen with BERT and GPT-4, involve using pre-trained models trained on massive amounts of text data. These models use complex neural networks to encode the context and meaning of the text, allowing them to achieve state-of-the-art accuracy on a wide range of NLP tasks, including sentiment analysis. However, these models require significant computational resources and may not be practical for all use cases.
- Lexicon-based analysis is a straightforward approach to sentiment analysis, but it may not be as accurate as more complex methods.
- Machine learning-based approaches can be more accurate, but they require labeled training data and may be more computationally expensive.
- Pre-trained transformer-based deep learning approaches can achieve state-of-the-art accuracy but require significant computational resources and may not be practical for all use cases.
The choice of approach will depend on the specific needs and constraints of the project at hand.
Source: https://www.datacamp.com/tutorial/text-analytics-beginners-nltk
Word2vec
Word2Vec is a popular and influential model for producing word embeddings introduced by a team of researchers at Google led by Tomas Mikolov in 2013. Word embeddings are dense vector representations of words that capture semantic meanings based on their usage in context. Word2Vec represents a breakthrough in the way computers interpret the semantic relationships between words by mapping these words into a high-dimensional space where the distance and direction between vectors help to define their relationships.
How Word2Vec Works
Word2Vec offers two architectures for generating word embedding: Continuous Bag-of-Words (CBOW) and Skip-Gram:
- Continuous Bag-of-Words (CBOW): This model predicts a target word from a set of context words surrounding it. For example, given the context words “the cat on the”, the model predicts the missing word “mat”. CBOW is faster and has better representations for more frequent words.
- Skip-Gram: This model works in the opposite way of CBOW; it uses a target word to predict context words. For example, given the word “apple”, it might predict context words like “fruit”, “red”, or “eat”. Skip-Gram works well with small datasets and represents well even rare words or phrases.
Both models are trained using a technique known as negative sampling, a simplified form of Noise Contrastive Estimation (NCE) that improves both the speed and quality of learning by randomly sampling negative examples to modify the weights rather than using the entire vocabulary, which can be computationally expensive.
Applications of Word2Vec
Word2Vec’s ability to capture semantic relationships and syntactic patterns within a corpus of text has led to its widespread application in many areas of natural language processing (NLP) and beyond:
- Semantic Analysis: Word2Vec embeddings can be used to assess the similarity between words or phrases, aiding in tasks like sentiment analysis, where the context of words around terms expressing sentiment is crucial.
- Language Translation: By mapping words from multiple languages into the same space based on their meanings, Word2Vec can assist in creating baselines for machine translation systems.
- Recommendation Systems: By understanding the relationships and similarities between different items (not just limited to words but also including any items that can be semantically represented), Word2Vec can improve the accuracy of recommendations in content-based filtering systems.
- Information Retrieval: Search engines can utilize Word2Vec to enhance the relevance of search results by understanding the semantic similarities between the terms used in a search query and the content available in the search index.
- Chatbots and Virtual Assistants: Word2Vec can help in understanding user queries by converting them into vectors and finding semantically relevant answers or actions.
- Enhanced Feature Generation: For more traditional machine learning tasks, Word2Vec can be used to generate more meaningful features from text data, which can then be used to train more effective models.
The introduction of Word2Vec has significantly influenced the development of more complex models like BERT, GPT (Generative Pre-trained Transformer), and others, each building upon or complementing the foundational ideas introduced by Word2Vec. As such, it remains a cornerstone technique in NLP, demonstrating the power of neural networks in understanding and processing language.
Limitations of word embeddings
Word embeddings are a powerful concept that can give your application a boost in the
performance, although they are not without limitation. One obvious issue is that they
cannot take context into account. Words you see in natural language are often polysemous, meaning they may have more than one meaning, depending on their context. However, because word embeddings are trained per token type, all the different
meanings are compressed into a single vector. For example, training a single vector for “dog” or “apple” cannot deal with the fact that “hot dog” or “Big Apple” are not a
type of animal or fruit, respectively. As another example, consider what “play” means
in these sentences: “They played games,” “I play Chopin,” “We play baseball,” and
“Hamlet is a play by Shakespeare” (these sentences are all from Tatoeba.org). These
occurrences of “play” have different meanings, and assigning a single vector wouldn’t
help much in downstream NLP tasks (e.g., in classifying the topic into sports, music,
and art). (from Hagiwara, 2021, ch9)
Is word2vec vector representation for each word?
Yes, exactly! Word2Vec creates a dense vector representation for each word in a given vocabulary. These vectors are of fixed dimensionality (e.g., 100, 200, 300 dimensions), and they capture the semantic meaning of words in a continuous vector space.
The key idea behind Word2Vec is that similar words have similar vector representations, meaning they are closer together in the vector space. For example, in a well-trained Word2Vec model, the vectors for “king” and “queen” would be closer together compared to the vectors for “king” and “dog” because “king” and “queen” are semantically related in terms of royalty, whereas “king” and “dog” are not.
This dense vector representation allows Word2Vec to capture various linguistic patterns and relationships between words, making it useful for a wide range of natural language processing tasks such as text classification, sentiment analysis, machine translation, and more.
Show me a vector representation of word2vec for the words, king, queen, dog, and cat.
Sure, I can’t provide the exact vectors as it would depend on the specific Word2Vec model used for training, including the dimensionality of the vectors and the specific embeddings learned during training. However, I can give you an example of what the vector representations might look like conceptually.
Let’s assume we’re working with a simplified Word2Vec model where each word is represented by a 3-dimensional vector. Here’s an example of what the vector representations might look like:
– “king”: [0.2, 0.5, 0.8]
– “queen”: [0.1, 0.6, 0.7]
– “dog”: [0.9, 0.3, 0.2]
– “cat”: [0.8, 0.4, 0.1]
In this hypothetical example, each word is represented by a 3-dimensional vector, where each dimension captures some aspect of the word’s meaning in the vector space. The values in each vector are arbitrary and chosen for illustrative purposes.
Keep in mind that in real Word2Vec models, the vectors would typically have much higher dimensionality (e.g., 100, 200, 300 dimensions), and the values would be learned during the training process based on the context in which the words appear in the training corpus.
Getting Started with KerasNLP https://keras.io/guides/keras_nlp/getting_started/
Text generation with an RNN https://www.tensorflow.org/text/tutorials/text_generation https://www.tensorflow.org/text/tutorials/nmt_with_attention https://www.tensorflow.org/text/tutorials/transformer text classification https://www.tensorflow.org/text/tutorials/classify_text_with_bert https://www.tensorflow.org/text/tutorials/text_classification_rnn https://www.tensorflow.org/text/tutorials/text_similarity NLP with BERT https://www.tensorflow.org/text/tutorials/bert_glue https://www.tensorflow.org/tfmodels/nlp/fine_tune_bert https://www.tensorflow.org/text/tutorials/uncertainty_quantification_with_sngp_bert
NLTK
Example from NLTK https://www.nltk.org/#:~:text=Natural%20Language%20Processing%20with%20Python,a%20nalyzing%20linguistic%20structure%2C%20and%20more >>> import nltk >>> sentence = """At eight o'clock on Thursday morning ... Arthur didn't feel very good.""" >>> tokens = nltk.word_tokenize(sentence) >>> tokens ['At', 'eight', "o'clock", 'on', 'Thursday', 'morning', 'Arthur', 'did', "n't", 'feel', 'very', 'good', '.'] >>> tagged = nltk.pos_tag(tokens) >>> tagged[0:6] [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN')]
Identify named entities
>>> entities = nltk.chunk.ne_chunk(tagged)
>>> entities
Tree('S', [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'),
('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'),
Tree('PERSON', [('Arthur', 'NNP')]),
('did', 'VBD'), ("n't", 'RB'), ('feel', 'VB'),
('very', 'RB'), ('good', 'JJ'), ('.', '.')])
Example # to tokenize text.split() # to create counter import collections collections.Counter() collections.Counter().most_common(10) # to remove special characters import re re.sub(r'[^\w]',' ', text) text.lower() import nltk nltk.download('stopwords') from nltk.corpus import stopwords stop_words = stopwords.words('english') for word in words: if word not in stop_words: words_no_stop.append(word) from nltk.stem import PorterStemmer for word in words_no_stop: words_clean.append(PorterStemer().stem(word)) from sklearn.feature_extraction.text import TfidfVectorizer # Build a vocabulary from our training text and transform training text training_dtm_tf = TfidfVectorizer(stop_words='english').fit_transform(training_text)
Spacy
from https://spacy.io/usage/spacy-101 import spacy text = """ Dave watched as the forest burned up on the hill, only a few miles from his house. The car had been hastily packed and Marta was inside trying to round up the last of the pets. "Where could she be?" he wondered as he continued to wait for Marta to appear with the pets. """ nlp = spacy.load("en_core_web_sm") doc = nlp(text) token_list = [token for token in doc] token_list
[
, Dave, watched, as, the, forest, burned, up, on, the, hill, ,,
, only, a, few, miles, from, his, house, ., The, car, had,
, been, hastily, packed, and, Marta, was, inside, trying, to, round,
, up, the, last, of, the, pets, ., ", Where, could, she, be, ?, ", he, wondered,
, as, he, continued, to, wait, for, Marta, to, appear, with, the, pets, .,
]filtered_tokens = [token for token in doc if not token.is_stop] filtered_tokens
[
, Dave, watched, forest, burned, hill, ,,
, miles, house, ., car,
, hastily, packed, Marta, inside, trying, round,
, pets, ., ", ?, ", wondered,
, continued, wait, Marta, appear, pets, .,
]lemmas = [
f"Token: {token}, lemma: {token.lemma_}"
for token in filtered_tokens
]
lemmas
['Token: \n, lemma: \n', 'Token: Dave, lemma: Dave',
'Token: watched, lemma: watch', 'Token: forest, lemma: forest',
# ...
]filtered_tokens[1].vector
array([ 1.8371646 , 1.4529226 , -1.6147211 , 0.678362 , -0.6594443 ,
1.6417935 , 0.5796405 , 2.3021278 , -0.13260496, 0.5750932 ,
1.5654886 , -0.6938864 , -0.59607106, -1.5377437 , 1.9425622 ,
-2.4552505 , 1.2321601 , 1.0434952 , -1.5102385 , -0.5787632 ,
0.12055647, 3.6501784 , 2.6160972 , -0.5710199 , -1.5221789 ,
0.00629176, 0.22760668, -1.922073 , -1.6252862 , -4.226225 ,
-3.495663 , -3.312053 , 0.81387717, -0.00677544, -0.11603224,
1.4620426 , 3.0751472 , 0.35958546, -0.22527039, -2.743926 ,
1.269633 , 4.606786 , 0.34034157, -2.1272311 , 1.2619178 ,
-4.209798 , 5.452852 , 1.6940253 , -2.5972986 , 0.95049495,
-1.910578 , -2.374927 , -1.4227567 , -2.2528825 , -1.799806 ,
1.607501 , 2.9914255 , 2.8065152 , -1.2510269 , -0.54964066,
-0.49980402, -1.3882618 , -0.470479 , -2.9670253 , 1.7884955 ,
4.5282774 , -1.2602427 , -0.14885521, 1.0419178 , -0.08892632,
-1.138275 , 2.242618 , 1.5077229 , -1.5030195 , 2.528098 ,
-1.6761329 , 0.16694719, 2.123961 , 0.02546412, 0.38754445,
0.8911977 , -0.07678384, -2.0690763 , -1.1211847 , 1.4821006 ,
1.1989193 , 2.1933236 , 0.5296372 , 3.0646474 , -1.7223308 ,
-1.3634219 , -0.47471118, -1.7648507 , 3.565178 , -2.394205 ,
-1.3800384 ], dtype=float32)Word embedding, gensim, topic modeling, LDA
Codes & Readings
https://www.geeksforgeeks.org/nlp-gensim-tutorial-complete-guide-for-beginners/ https://www.machinelearningplus.com/nlp/gensim-tutorial/ https://radimrehurek.com/gensim/auto_examples/index.html https://radimrehurek.com/gensim/models/word2vec.html https://www.machinelearningplus.com/nlp/topic-modeling-gensim-python/ https://www.machinelearningplus.com/nlp/gensim-tutorial/ https://topic-modeling.pythonhumanities.com/intro.html Topic extraction with Non-negative Matrix Factorization and Latent Dirichlet Allocation — scikit-learn 1.4.2 documentation https://repub.eur.nl/pub/116043/annals.2017.0099.pdf Measuring Corporate Culture Using Machine Learning | The Review of Financial Studies | Oxford Academic (oup.com)
https://repub.eur.nl/pub/116043/annals.2017.0099.pdf Analyst Information Discovery and Interpretation Roles: A Topic Modeling Approach | Management Science (informs.org) Measuring Corporate Culture Using Machine Learning | The Review of Financial Studies | Oxford Academic (oup.com)
https://nbviewer.org/github/cyrus723/my-first-binder/blob/main/LDA_Kochmar2022_NLP_book_CH10.ipynb https://github.com/PacktPublishing/Machine-Learning-for-Algorithmic-Trading-Second-Edition_Original/blob/master/16_word_embeddings/05_financial_news_word2vec_gensim.ipynb https://nbviewer.org/github/cyrus723/my-first-binder/blob/main/embedding_gensim_sentiment1.ipynb https://nbviewer.org/github/cyrus723/my-first-binder/blob/main/nlp_lda_model_gensim1_spacy.ipynb#topic=4&lambda=1&term= from gensim.utils import tokenize from gensim.parsing.preprocessing import preprocess_string,strip_tags,strip_punctuation,strip_numeric,remove_stopwords,strip_short from gensim.corpora.dictionary import Dictionary from gensim import models from gensim.models.ldamodel import LdaModel lda_bow = LdaModel(dataset_corpus_bow,num_topics=20,id2word=dataset_dictionary,random_state=0) output: (0, '0.013*"space" + 0.006*"nasa" + 0.006*"earth" + 0.006*"writes" + 0.005*"edu" + 0.005*"shuttle" + 0.004*"gamma" + 0.004*"article"') (1, '0.014*"edu" + 0.008*"university" + 0.008*"mail" + 0.007*"information" + 0.006*"list" + 0.005*"com" + 0.005*"address" + 0.005*"research"') (2, '0.014*"writes" + 0.012*"article" + 0.010*"like" + 0.007*"car" + 0.007*"edu" + 0.007*"people" + 0.006*"think" + 0.006*"know"') (3, '0.007*"health" + 0.006*"edu" + 0.005*"writes" + 0.005*"insurance" + 0.005*"private" + 0.004*"pictures" + 0.004*"canada" + 0.003*"care"')
LDA, Topic Modelling
LDA: Unveiling Hidden Themes in Your Text Data by Google Gemini
Imagine you have a collection of news articles on various topics. LDA, or Latent Dirichlet Allocation, is a technique that helps you automatically discover the underlying themes in those articles. It’s like having a superpowered librarian who can sort through the articles and tell you the main subjects without needing any pre-defined categories.
Here’s a breakdown of how LDA works:
- The Big Picture: LDA assumes that each document is a mixture of several hidden topics, and each topic is a distribution of words. For instance, an article about climate change might be a mix of “environment,” “politics,” and “science” topics.
- Probabilistic Dance: LDA uses a probabilistic approach to figure out these hidden topics and how likely each word belongs to each topic. It’s like flipping a weighted coin for each word, where the weights represent the topic probabilities.
- Finding the Sweet Spot: Through an iterative process, LDA adjusts these topic probabilities and word-to-topic associations until it reaches a stable state that best explains the entire collection of documents.
Real-World Example: Unveiling Customer Reviews
Let’s say you’re an e-commerce business owner, and you want to understand the main themes in your customer reviews. LDA can help you discover topics like:
- Product Quality: Words like “durable,” “well-made,” and “disappointed” might be prominent.
- Customer Service: Words like “helpful,” “responsive,” and “frustrated” might be key.
- Value for Money: Words like “affordable,” “worth the price,” and “overpriced” might be indicative.
By uncovering these topics, you can gain valuable insights into how customers perceive your products and services, allowing you to make data-driven decisions for improvement.
Important Note: LDA is Different from LDL
It’s important to clarify that LDL (Latent Dirichlet Learning) is not a commonly used term in topic modeling. There might be some confusion with LDA (Latent Dirichlet Allocation). LDA is the established technique for this type of unsupervised learning on documents.
Additional Considerations
- Number of Topics: Choosing the right number of topics in LDA is crucial. Too few, and you might miss important themes. Too many, and you might end up with overly specific or uninterpretable topics.
- Preprocessing: Cleaning your text data by removing stop words (common words like “the” and “a”) and stemming/lemmatization (reducing words to their root form) can improve LDA’s performance.
By understanding LDA and using it effectively, you can unlock valuable hidden themes in your text data, leading to better decision-making in various domains.
Topic Modeling: LDA (Latent Dirichlet Allocation) by meta.ai
LDA is a popular topic modeling technique used to extract hidden topics from a large corpus of text data. It’s like uncovering underlying themes or patterns in a collection of documents.
Simple Explanation:
Imagine you have a huge library with thousands of books. Each book represents a document, and each document contains a mix of topics (themes). LDA helps you identify the underlying topics (themes) in each document and the entire library.
Real-World Example:
Suppose we have a collection of news articles from different sources. We want to identify the underlying topics (themes) in these articles. After applying LDA, we might discover the following topics:
-
Topic 1: Politics (articles about government policies, elections, etc.)
-
Topic 2: Technology (articles about new gadgets, innovations, etc.)
-
Topic 3: Sports (articles about games, players, etc.)
Each article may contain a mix of these topics, and LDA helps us understand the proportion of each topic in each article.
LDL Algorithm (Latent Dirichlet Allocation)
-
Tokenize the text data (split into individual words)
-
Remove stop words (common words like “the,” “and,” etc.)
-
Convert words to numerical representations (word embeddings)
-
Set the number of topics (K)
-
Initialize topic weights (θ) and word weights (φ) randomly
-
For each document (d) and word (w):
-
Calculate the topic assignment (z) for word w in document d
-
Update the topic weights (θ) for document d
-
Update the word weights (φ) for topic k
-
-
Update the topic weights (θ) and word weights (φ) using the calculated values from the E-Step
-
Repeat the E-Step and M-Step until convergence or a specified number of iterations
-
Topic assignments (z) for each word in each document
-
Topic weights (θ) for each document
-
Word weights (φ) for each topic
By understanding the topic weights and word weights, we can identify the underlying topics in the corpus and the words that are most representative of each topic.
LDA (Latent Dirichlet Allocation) by Open AI Chat GPT
Explanation in Simple Terms:
LDA is a type of topic modeling, which is a method used to discover the abstract topics that occur in a collection of documents. Think of it as a way to automatically organize, understand, and summarize large sets of textual information.
- Documents and Topics: Imagine you have a large number of documents (e.g., articles, books, tweets). LDA assumes that each document is a mixture of various topics, and each topic is a mixture of words.
- Word Distribution: Each topic has a probability distribution over words (some words are more likely to appear in a topic than others). Similarly, each document has a probability distribution over topics (some topics are more likely to be discussed in a document than others).
- Process: LDA tries to figure out which topics are present in the documents and which words are associated with each topic. It does this by iteratively adjusting the topic-word and document-topic distributions to better fit the observed data (the words in the documents).
Real-World Example:
Imagine you run a library and have a large collection of books. You want to know what the main themes (or topics) are without reading every single book. LDA can help by:
- Input: You feed the text of all the books into the LDA algorithm.
- Output: The algorithm identifies, for example, five topics: History, Science, Literature, Technology, and Art.
- Results:
- A book on “The History of Technology” might be identified as 60% Technology and 40% History.
- A book on “Modern Art Techniques” might be 70% Art and 30% Literature.
- For each topic (e.g., Technology), the algorithm will list the most relevant words like “innovation,” “computers,” “engineering,” etc.
LDL (Latent Dirichlet Allocation with Local Density)
While LDA is a well-known topic modeling technique, LDL (Local Density Latent Dirichlet Allocation) is not a standard or widely recognized term in the context of topic modeling or machine learning. However, I can explain a concept that combines LDA with a focus on local density, which might be what you’re referring to.
Explanation in Detail:
LDL could potentially refer to an approach that enhances LDA by incorporating local density information to improve the discovery of topics, especially in documents with complex structures or local variations in word usage.
- Local Density Concept: Local density refers to the concentration of data points (or words) in a local region of the document space. In the context of topic modeling, this means paying attention to clusters of words that frequently occur together in specific parts of the documents.
- Improved Topic Discovery: By integrating local density information, LDL could better identify topics that are contextually relevant in specific sections of documents, leading to more accurate and nuanced topic models.
Steps in LDL (Hypothetical):
- Preprocessing: Similar to LDA, start by preprocessing the text data (tokenization, stop word removal, etc.).
- Local Density Analysis: Analyze the local density of words within documents to identify clusters of words that frequently co-occur.
- Modified LDA: Incorporate this local density information into the LDA algorithm. Adjust the probability distributions to give more weight to words that are densely clustered in local contexts.
- Inference: Run the modified LDA algorithm to infer the topic-word and document-topic distributions, now enhanced by local density considerations.
Potential Advantages:
- Better Contextual Understanding: By focusing on local word clusters, LDL can capture more context-specific topics.
- Improved Accuracy: Topics identified might be more accurate and relevant to specific sections of documents.
Example:
Suppose you have a large collection of customer reviews for different electronic products. Standard LDA might identify broad topics like “Features,” “Performance,” and “Design.” However, some reviews might discuss very specific aspects of a product in detail.
Using LDL:
- Local Clusters: The algorithm identifies local clusters of words within the reviews, such as a cluster around “battery life” and “charging speed” in the “Performance” topic.
- Enhanced Topics: The topics are refined to include these local clusters, resulting in more specific topics like “Battery Performance” and “Display Quality.”
Results:
- A review might be identified as discussing 50% “Battery Performance” and 50% “Design.”
- The “Battery Performance” topic would include words like “battery life,” “charging speed,” “power efficiency,” etc.
Conclusion
While LDA is a well-established method for topic modeling, incorporating local density (hypothetical LDL) can potentially enhance the accuracy and contextual relevance of the discovered topics. Understanding these techniques can help in organizing and analyzing large textual datasets more effectively.
Documents can in turn be represented in terms of a mixture of these topics. A unique feature of LDA models is that topics are not required to be distinct, and words may occur in multiple topics; this allows for a kind of topical fuzziness that is useful for handling the flexibility of language. (from “Applied Text Analystics” by Benjamin Bengfort, Rebecca Bilbro, and Tony Ojeda, 2018, Ch 6)
Suppose you work as a content manager for a large news platform. Your platform hosts texts from a wide variety of authors and mainly specializes in the following set of well-established topics: “Politics”, “Finance”, “Science”, “Sports”, and “Arts”. Your task is to decide, for every incoming article, which topic it belongs to and post it under the relevant tab on the platform…….. you can apply to the task at hand is to use an ML classifier trained on the articles that were assigned with topics in the past, using words occurring in these articles as features…….. This is a supervised approach (From Kochmar, 2022, “Getting Started with NLP”)
In Kochmar 2022, this supervised approach has many unrealistic issues so it is not easily implementable. For example, those labeled classification training sets are not simply available. So, alternatively, the clustering approach can be considered. “One aspect not addressed by this clustering algorithm is the possibility that some posts may naturally cover more than one topic. ” (From Kochmar, 2022, “Getting Started with NLP”)
The LDA algorithm treats each document (text, post, etc.) as a mixture of topics. Each topic, in its turn, is composed of certain words, so once the topic or topics for the document are determined, these topics become the driving forces that are assumed to have produced the words in the document based on the word sets these topics comprise (e.g., {car, engine, speed, …} or {deal, sale, price, …}). This is the theoretical assumption behind LDA: the words that you observe in documents are not put together in these documents in a random manner. Rather it is believed that these words are thematically related – some are related, e.g., to autos and others to sales. All you can observe in practice is the words themselves, but the algorithm assumes that, behind the scenes, these words are generated and put together in the documents by such abstract topics. Since the topics are hidden from the eye of the observer or, to use a technical term, they are latent, this gives the algorithm its name. The goal of the algorithm then is to reverse-engineer this document generation process to detect which topics are responsible for the observed words. (From Kochmar, 2022, “Getting Started with NLP” CH 10)
LDA assumes that each document is a mixture (linear combination) of some arbitrary number of topics that you select when you begin training the LDA model. LDA also assumes that each topic can be represented by a distribution of words (term frequencies). The probability or weight for each of these topics within a document, as well as the probability of a word being assigned to a topic, is assumed to start with a Dirichlet probability distribution (the prior if you remember your statistics). This is where the algorithm gets its name. (Lane et al, 2021)
- Semantic analysis:
-
- Word embedding from computer science literature is also a popular tool to entangle interactions among words to derive semantic meanings.
- Word embedding is a shallow neural network approach
- Assumes that similar words are neighboring with each other
- Topic modelling:
-
-
- Latent Dirichlet Allocation (LDA), the unsupervised classification method has been used in several recent studies to collect representative topics in a document.
- Proposed first by Blei, David M, Andrew Y Ng, and Michael I Jordan, 2003, Latent dirichlet allocation, Journal of Machine Learning Research 3, 993–1022.
- It is a dimensionality reduction algorithm used extensively in computational linguistics.
- Assume that a corpus of documents can be represented by a set of topics.
- LDA is a probabilistic approach, while LSA (Latent Semantic Analysis) a linear algebra approach with singular value decomposition (SVD).
- A method for Bayesian unsupervised classification of documents, similar to clustering on numeric data.
-
- Assumptions
- Every document comprises a statistical distribution of topics that can be obtained by combining all the distribution for all the topics covered. That is, a corpus of documents can be represented by a set of topics.
- The document generation process arises from an underlying topic distribution, and not an individual word distribution.
- Discover the abstract “topics” that occur in a collection of documents even when we’re not sure what we’re looking for.
- Applications:
- Customer feedback analysis, Document clustering, Recommendation engines
- Discover the hidden themes in the collection, find patterns, infer topics, and classify the documents into the discovered themes.
- Use the classification to organize/summarize/search the documents.
- Gensim is an open source Python library for natural language processing, with a focus on topic modeling.
- LDA discovers clusters of text (“topics”) that frequently appear in a corpus.
- Provides a cluster of topic words, but it also provides an estimate of the importance of each topic in each document.
- A particular topic is characterized as a distribution over this common vocabulary of words where the relative probability weight assigned to each word indicates its relative importance to that topic.
- A topic is thus a word vector where each element is the weight associated with that word.
- “For example, the words “oil” and “electricity” might be important to topics associated with Natural Resources and Manufacturing, but one might expect oil to receive a higher weighting than electricity in the Natural Resources topic. The opposite might be true for the Manufacturing topic.”
- Advantages: Objective for human ability to detect topics.
- Does not require any prior knowledge about the content of the documents; rather, the algorithm identifies the topics.
- A topic is defined as a group of words that tend to appear in the same context.
- Words used in conjunction with or in the same neighbourhood of each other will tend to be categorized together.
- LDA is replicable, and is automated so it cannot be influenced by researcher prejudice.
- This contrasts with existing textual approaches that rely on researcher-selected lists of words.
- More sophisticated structure than the dictionary “bag of words” approach
- Because the same word, when used in different contexts, can be classified into different topics.
- For instance, the meaning of the word “cash” is found within different categories, but it tends to be associated with different words in different cases.
- The phrase “cash flow” is more likely to refer to financial statements and thus pertain to accounting issues, whereas the phrase “cash bonus” tends to refer to compensation.
- In sum, the LDA determines the context in which a word is used.
- It requires only one input: the number of topics T to be generated.
- A TF-IDF is unable to understand the semantics of words, or the position of a word in text.
- LDA is a generative model, meaning that it outputs all the possible outcomes.
- While relatively common within the computer science literature, LDA has only recently began to be used in finance.
- Firm disclosures are related to firm-specific shocks to production. (Wu, 2017)
- The 10K disclosures by fraudulent managers differ from other firms. Hoberg and Lewis (2017)
- Using LDA, authors investigate the completeness of loan contracts. Ganglmair and Wardlaw (2017)
- Using LDA, one can forecast the emerging risk factors in the financial sector. (Hanley & Hoberg, 2019)
- Three topics, identified by the LDA, can explain the lengthened financial statements. (Dyer, Lang & Stice-Lawrence, 2019)
- Analysts play the information intermediary roles by discovering information beyond corporate disclosures. (Huang et. al., 2018)
- The text-based measure gives a useful description of innovation by firms. (Bellstam, Bhagat & Cookson, 2021)
- The text-based measures from Glassdoor are useful in predicting corporate misconduct. (Campbell & Shang, 2022)
- Criticism
- The economic interpretation of individual topics is often ambiguous, as LDA does not generate a specific label for each topic.
- For example, if the selected number of topics is too few or if factors are too correlated, they will be grouped by LDA into a single risk topic, making the interpretation unclear.
- If, on the other hand, the selected number of topics is too many, individual risks might be split into more than one factor.
- Second, when LDA is run on the corpus of documents in each year, the composition of the pre-set number of LDA topics will likely change, making it difficult (if not impossible) to track specific risks through time.
- The economic interpretation of individual topics is often ambiguous, as LDA does not generate a specific label for each topic.
seq2seq
Seq2Seq models consist of an encoder and a decoder. The decoder takes a sequence of tokens in the source language and runs it through an RNN, which produces a fixed-length vector at the end. This fixed-length vector is a representation of the input sentence. The decoder, which
is another RNN, takes this vector and produces a sequence in the target language, token by token.
The size of the vector is fixed no matter how long (or how short) the source sentence is. The intermediate vector is a huge bottleneck. (from Hagiwara, 2021, Ch 8)
transformer
Transformers use self-attention mechanisms to capture relationships between words in a sequence, enabling them to understand context and generate coherent responses. …. Unlike earlier models, transformers can process input sequences in parallel, allowing for faster processing and handling of longer input sequences, making them efficient and suitable for a wide range of tasks.
- The encoder processes the input prompt, capturing its meaning and context.
- The decoder generates the output based on the encoder’s representation and the provided prompt.
- Self–attention allows the model to weigh the importance of different words in the input prompt, capturing relationships and context.
- Positional encodings are added to the input embeddings to provide information about the position of each word in the sequence.
Instead of relying on a single, fixed-length vector to represent all the information in a
sentence, the decoder would have a much easier time if there was a mechanism where
it can refer to some specific part of the encoder as it generates the target tokens. This
is similar to how human translators (the decoder) reference the source sentence (the
encoder) as needed.
This can be achieved by using attention, which is a mechanism in neural networks
that focuses on a specific part of the input and computes its context-dependent summary. It is like having some sort of key-value store that contains all of the input’s information and then looking it up with a query (the current context). The stored values
are not just a single vector but usually a list of vectors, one for each token, associated
with corresponding keys. This effectively increases the size of the “memory” the
decoder can refer to when it’s making a prediction. (from Hagiwara, 2021, Ch 8)
How exactly transformer model proposed in 2017 predict the next work in NLP
-
Input Preparation: The transformer first breaks down the sentence into individual words or pieces (tokens). These tokens are converted into numerical representations for the model to understand.
-
Self-Attention: Unlike traditional models that process words sequentially, transformers use self-attention. This allows each token to “attend” to all the other tokens in the sentence simultaneously. By attending, the model considers the relationships between words to understand the context.
-
Understanding the Context: Through self-attention, the model builds a deeper understanding of each word’s meaning based on its connection to other words. This allows it to grasp the overall sentence structure and meaning.
-
Prediction: With the contextual understanding, the transformer predicts the next word that statistically follows the current sequence. It considers the surrounding words and the overall sentence meaning to make an educated guess about the most likely continuation.
Essentially, transformers analyze the entire sentence at once to understand the relationships between words, allowing for more accurate predictions. This is a significant improvement over previous models that relied on sequential processing.
For further details, you can explore resources on self-attention and how transformers work in NLP:
- Transformer models: the future of natural language processing explains transformers and self-attention.
- How do Transformers work? provides a more in-depth look at the transformer architecture.
Sentence: The cat sat on the mat.
-
Tokenization: The transformer first breaks the sentence into individual words: “The”, “cat”, “sat”, “on”, “the”, “mat”.
-
Self-Attention: Here’s where it gets interesting. The transformer doesn’t just process these words one by one. Instead, it uses self-attention to analyze all the relationships between them at once.
- When considering “cat,” it might attend to “sat” more strongly, understanding the action related to the cat.
- When looking at “the” (second occurrence), it might pay more attention to “mat” since they likely refer to the same thing.
By attending to these connections, the transformer builds a context for each word.
-
Understanding the Context: Through self-attention, the transformer grasps that “cat” is the subject doing the action of sitting, likely on a designated resting area (“mat”).
-
Prediction: Now, imagine we want to predict the next word after “mat.” With the built context, the transformer understands the sentence talks about a location where the cat sits. So, it’s unlikely the next word is something unrelated like “jump” or “eat.” It would focus on words that fit the scenario, like “comfortably” or “happily.”
Key takeaway: By analyzing relationships between all words simultaneously, the transformer goes beyond just the order to capture the true meaning and predict the next word more accurately.
This is a simplified example, but it highlights how transformers leverage self-attention for a deeper understanding of language.
Transformer models differentiate the meaning of “model” in the two sentences through a combination of techniques:
- Surrounding Words: The model analyzes the words surrounding “model” in each sentence.
- In the first sentence (“the transformer model”), “transformer” provides a clear clue. It indicates “model” refers to a type of computer program used for analysis.
- In the second sentence (“fashion models”), “fashion” suggests “model” refers to a person who showcases clothing.
- Part-of-Speech Tagging: Transformers can identify the grammatical role (part-of-speech) of each word.
- In the first sentence, “model” is likely a noun (the transformer model).
- In the second sentence, “models” is likely a verb (a fashion models).
- Contextual Information: Transformers are trained on massive amounts of text data. This data provides contextual understanding of how words are typically used.
- The model has likely encountered “transformer model” as a technical term used in NLP (Natural Language Processing).
- Similarly, it’s familiar with “fashion model” as a profession in the fashion industry.
By combining these factors, the transformer model effectively distinguishes between the two meanings of “model” in the sentences. It leverages the surrounding words, grammatical role, and its knowledge of how language is used to assign the most probable meaning in each context.
transformer BERT tokenizer
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tokenizer_output = tokenizer.tokenize("This is an example of the bert tokenizer")
print(tokenizer_output)
output:
# ['this', 'is', 'an', 'example', 'of', 'the', 'bert', 'token', '##izer']
transformer sentiment analysis
To perform sentiment analysis on financial news using the BERT model, you can utilize the Hugging Face transformers library, which provides pre-trained models and makes it straightforward to apply these models to various NLP tasks, including sentiment analysis.
Here’s a Python code example to guide you on how to set this up:
Step 1: Install the Necessary Libraries
You will need to install the transformers and torch libraries from Hugging Face. You can install them using pip:
pip install transformers torch
Step 2: Python Code for Sentiment Analysis Using BERT
from transformers import pipeline
def sentiment_analysis(text):
# Load the sentiment analysis pipeline with the BERT model
classifier = pipeline("sentiment-analysis", model="nlptown/bert-base-multilingual-uncased-sentiment")
# Perform sentiment analysis
result = classifier(text)
return result
# Example usage:
financial_news = "The stock market experienced a significant downturn today amid concerns over inflation."
result = sentiment_analysis(financial_news)
print("Sentiment Analysis Result:", result)
output:
Sentiment Analysis Result: [{'label': '2 stars', 'score': 0.47418859601020813}]
Explanation:
- Pipeline Setup: The
pipelinefunction from Hugging Face creates a pipeline for sentiment analysis. Here, we’re using the “nlptown/bert-base-multilingual-uncased-sentiment” model, which is a BERT model fine-tuned for sentiment analysis on multilingual data. This model can classify sentiments into categories such as positive, neutral, and negative, which suits financial news well. - Performing Analysis: The
classifierfunction takes a string of text and returns a sentiment classification, which includes a label (e.g., “positive”, “neutral”, “negative”) and a confidence score. - Model Choice: The chosen model (
nlptown/bert-base-multilingual-uncased-sentiment) is particularly useful if your financial news might come from various languages, but you can choose other models that might be more specific to your language requirements or the level of analysis detail you need.
This setup will allow you to quickly and effectively analyze the sentiment of financial news articles using BERT with Python.
Interpretation:
- Label Interpretation: The label ‘2 stars’ suggests that the sentiment expressed in the text you analyzed is generally negative. In sentiment rating systems where labels are presented as stars (often ranging from 1 star to 5 stars), a rating of 2 stars typically denotes dissatisfaction or a negative view. It implies that the text likely contains criticisms or less favorable opinions.
- Score Interpretation: The confidence score of approximately 0.474 (or 47.4%) associated with this label indicates a moderate level of confidence in the assessment. This isn’t a very high confidence level, which might suggest that the sentiment expressed in the text was not overwhelmingly clear or that the text contained mixed sentiments, making it harder for the model to assign a more definitive sentiment rating with higher confidence.
Considerations:
- Model Sensitivity: This moderate confidence level might also reflect the sensitivity of the model to the specific language used in the text. Some nuances or less explicit sentiment expressions might not be as easily recognized by the model.
- Context Dependence: Sentiment analysis can be context-sensitive. The interpretation of certain phrases might depend heavily on the surrounding text or the specific industry context (like financial news versus a product review).
Next Steps:
- Further Analysis: If precision is critical for your application, consider analyzing more samples to see if the model consistently assigns similar scores and labels under similar conditions.
- Cross-Validation: You might also want to cross-validate these results with another sentiment analysis model or approach to check consistency and reliability, especially given the moderate confidence level.
- Model Training: If you frequently encounter moderate or low confidence scores, it might be beneficial to fine-tune the model on a more specific dataset or a dataset that closely matches the type of text you are analyzing.
This should help you understand and utilize the results from your sentiment analysis more effectively. If you have more text samples or need further analysis, adjusting the model or its inputs might be necessary.
BERT
https://research.google/blog/open-sourcing-bert-state-of-the-art-pre-training-for-natural-language-processing/ https://huggingface.co/docs/transformers/en/model_doc/bert https://www.youtube.com/watch?v=t45S_MwAcOw https://www.geeksforgeeks.org/explanation-of-bert-model-nlp/
https://www.geeksforgeeks.org/explanation-of-bert-model-nlp/ from transformers import BertTokenizer # Load pre-trained BERT tokenizer tokenizer = BertTokenizer.from_pretrained("bert-base-cased") # Input text text = 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. ' # Tokenize and encode the text encoding = tokenizer.encode(text) # Print the token IDs print("Token IDs:", encoding) # Convert token IDs back to tokens tokens = tokenizer.convert_ids_to_tokens(encoding) # Print the corresponding tokens print("Tokens:", tokens)
FinBERT
https://medium.com/prosus-ai-tech-blog/finbert-financial-sentiment-analysis-with-bert-b277a3607101 https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3910214
FINBERT is a variant of the popular BERT (Bidirectional Encoder Representations from Transformers) model, specifically tailored for applications in the financial sector. This adaptation of BERT is aimed at better understanding and processing the unique language and terminology used in financial texts. Here’s a breakdown of its main aspects:
1. Base Model: BERT
- BERT is a transformer-based machine learning model for natural language processing (NLP) developed by Google. It’s designed to pre-train deep bidirectional representations by conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of NLP tasks.
2. Domain-Specific Training
- FINBERT is further trained (or fine-tuned) on financial texts. This includes corporate reports, financial news articles, and analytical notes, which help the model grasp the nuances of financial jargon and context better than the standard BERT model. This step is crucial for the model to perform well on domain-specific tasks.
3. Applications in Finance
- Sentiment Analysis: One of the primary applications of FINBERT is to assess the sentiment of financial texts. This can involve determining whether a given report, article, or note has a positive, negative, or neutral tone regarding stocks, markets, or economic outlooks.
- Information Extraction: FINBERT can be used to extract specific financial information from unstructured text, such as company names, financial metrics, and market trends.
- Regulatory Compliance: It can help in automating the monitoring of texts to ensure compliance with financial regulations by identifying problematic content or discrepancies in financial documentation.
4. Performance and Adaptation
- By training on a specialized corpus, FINBERT can achieve higher accuracy in understanding and generating insights from financial documents compared to general-purpose models. Its effectiveness depends largely on the quality and relevance of the training data, as well as how well the model’s parameters are tuned during the training process.
5. Challenges and Limitations
- Context Understanding: Financial texts often contain complex concepts and relationships that can be challenging for any model, including FINBERT, to fully understand.
- Data Sensitivity: Financial data is often sensitive and proprietary, posing challenges in obtaining large, diverse datasets for training.
- Model Maintenance: Financial language evolves with market conditions and regulatory changes, requiring ongoing updates to the model to maintain its performance.
Overall, FINBERT exemplifies how BERT’s architecture can be specialized for distinct industry needs, enhancing the model’s utility and effectiveness in sector-specific applications.
To demonstrate how to use FINBERT with real financial data for sentiment analysis, let’s go through an example where we use Python to analyze the sentiment of financial news headlines. First, we’ll need a pre-trained FINBERT model. For this example, we will assume that we’re using a FINBERT model that is available through the Hugging Face’s Transformers library, which provides an easy-to-use interface for many pre-trained models.
Step-by-Step Example:
First, you need to install the necessary Python libraries if they are not already installed:
pip install transformers pandas
from transformers import pipeline
# Initialize the sentiment analysis model
model_name = "yiyanghkust/finbert-tone"
finbert = pipeline("sentiment-analysis", model=model_name)
# Function to analyze sentiment
def analyze_sentiment(text):
results = finbert(text)
return results
# Example usage:
financial_news = "The company's revenue has exceeded expectations, but concerns about regulatory challenges remain."
sentiment_result = analyze_sentiment(financial_news)
# Print the results
print("Sentiment Analysis Result:", sentiment_result)
output:
Sentiment Analysis Result: [{'label': 'Positive', 'score': 0.9999998807907104}]
LLM
What Is Retrieval-Augmented Generation aka RAG
https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
Repurposing and Fine-Tuning
https://www.turing.com/resources/finetuning-large-language-models
Chat GPT
Training a Large Language Model (LLM) like GPT (Generative Pretrained Transformer) involves several key steps that allow the model to understand and generate human-like text based on the data it’s been trained on. Here’s an overview of the training process:
- Data Collection: The first step in training an LLM is gathering a large and diverse dataset. This dataset typically consists of text from books, websites, articles, and other sources that cover a wide range of topics. The diversity in the data helps the model learn various language patterns, styles, and information.
- Tokenization: Once the data is collected, it’s broken down into smaller pieces called tokens. These tokens can be words, parts of words, or even punctuation. Tokenization helps in simplifying the processing of large texts and allows the model to handle different languages and special characters effectively.
- Pretraining: During pretraining, the model learns to predict the next word in a sentence by looking at the words that come before it (this is known as autoregressive training). For models like BERT (Bidirectional Encoder Representations from Transformers), the training also involves predicting a word that’s been masked in a sentence, helping the model to understand context from both directions (left and right of the masked word).
- Transfer Learning: After the initial pretraining, the model can be fine-tuned for specific tasks. This involves additional training on a smaller, task-specific dataset. For example, if the model needs to perform sentiment analysis, it would be fine-tuned on a dataset containing text labeled with sentiments.
- Training Parameters: Throughout the training process, various parameters within the model are adjusted based on how well the model’s predictions match the actual data. This involves complex algorithms to minimize errors and improve the model’s accuracy.
- Evaluation and Iteration: After training, the model’s performance is evaluated using separate validation datasets not seen during the training phase. Based on the results, adjustments might be made, and additional training may occur to optimize the model’s performance.
- Deployment: Once trained and fine-tuned, the model is ready to be deployed in real-world applications, where it can generate text, answer questions, summarize content, translate languages, and more based on the patterns and knowledge it has learned during training.
The goal of training LLMs is to develop a model that can understand and generate text in a way that mimics human language, providing useful and coherent responses or insights. The complexity and resource requirements for training such models are significant, often involving large computational resources and specialized hardware like GPUs.
Papers https://www.sciencedirect.com/science/article/pii/S266734522300024X https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4402499 https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4391863 https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4316650 https://mgmt.wharton.upenn.edu/profile/emollick/ https://arxiv.org/abs/2305.18339 https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4429658 https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4322651 https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4660148 https://arxiv.org/pdf/2403.14380 https://bfi.uchicago.edu/wp-content/uploads/2023/04/BFI_WP_2023-59.pdf https://rpc.cfainstitute.org/-/media/documents/article/industry-research/unstructured-data-and-ai.pdf https://rpc.cfainstitute.org/-/media/documents/article/rf-brief/ai-and-big-data-in-investments.pdf
BloombergGPT
BloombergGPT is a specialized version of a large language model tailored specifically for financial data and applications. This model leverages Bloomberg’s vast repository of proprietary financial data, including financial reports, market analyses, news articles, and other relevant financial documentation. Here are some key points about BloombergGPT:
- Training and Data: BloombergGPT is trained on a mix of 363 billion tokens from Bloomberg’s proprietary datasets and 345 billion tokens from general-purpose datasets. This extensive training helps the model to develop a deep understanding of financial contexts and terminology.
- Purpose and Use: The primary goal of BloombergGPT is to provide finance-specific insights and analytics, making it an invaluable tool for financial analysts, investors, and other market participants. It’s designed to integrate and analyze complex financial data sets, extracting meaningful insights that can drive investment decisions.
- Customization and Performance: Unlike generic language models that are trained on broad data from various domains, BloombergGPT’s training on specialized financial data allows it to perform exceptionally well in tasks that require a deep understanding of the financial sector. This customization makes it particularly useful for analyzing financial texts, generating reports, and even predicting market trends based on historical data.
- Technological Advancement: By using a language model specifically tuned for financial applications, Bloomberg leverages its industry expertise and unique data assets to create a tool that can significantly enhance productivity and decision-making in finance.
- Integration: BloombergGPT is not just a standalone tool but is designed to be integrated into Bloomberg’s existing suite of financial analysis tools and platforms. This integration ensures that users can seamlessly utilize the model within their regular workflows.
In summary, BloombergGPT represents a significant advancement in applying AI and language models within the financial industry, providing tailored solutions that enhance understanding and decision-making from complex datasets.
